 今日は、ウェブサイトやブログなどでどのURLがアクセスを稼いでいるのかを把握する方法を紹介します。
今日は、ウェブサイトやブログなどでどのURLがアクセスを稼いでいるのかを把握する方法を紹介します。
使うのは、Google Search Consoleとスプレッドシートだけです!
- サイトのSEO評価にどのURLがアクセスを稼いでいるのか把握したい
- Google SpreadSheetのImportXML関数を使おう
- ImportXMLでタイトルを抽出する
- ImportXMLのデータ抽出に時間がかかる、遅い時はどうする?
サイトのSEO評価にどのURLがアクセスを稼いでいるのか把握したい
ウェブサイトやブログの集客は、ユーザーが求めている記事をどれだけ多く作れるかになります。Google Search Consoleを使えば、どのURLがページのアクセスを稼いでいるのか直感的に把握することができます。
アクセス数を稼いでいるページのコンテンツを修正するもよし、アクセス数を稼いでいるページへ、誘導するコンテンツを増やしても良いですが、どのページがアクセスを稼いでいるのかSearch Console上だと直感的に分かりにくいことがありませんか?
というのも、Search ConsoleではページのタイトルではなくURLに対してクリック数やインプレッション数を表示してくれる機能があるのですが、どのURLがどんな記事か思い出すのに時間がかかってしまいます。
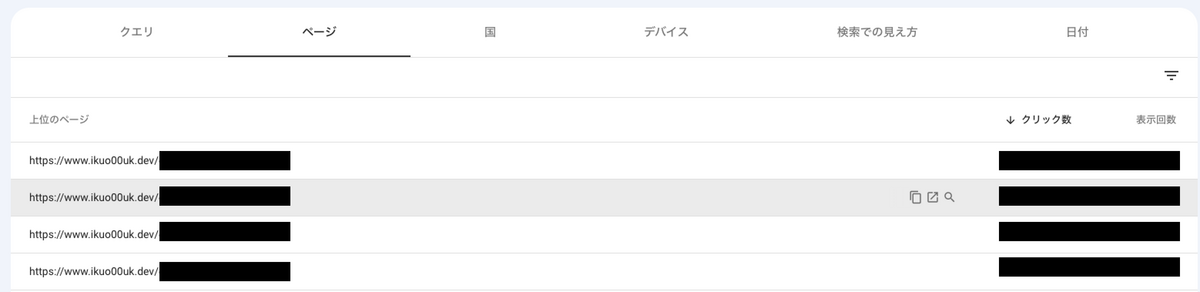 ※参考までに画像を添付。どのURLかとアクセス数は黒塗りさせていだきます
※参考までに画像を添付。どのURLかとアクセス数は黒塗りさせていだきます
こちらをURLのタイトルに置き換えることで、直感的にどのページがアクセスを稼いでいるのか把握することができます。
Google SpreadSheetのImportXML関数を使おう
まずは、SearchConsoleからデータをエクスポートして、Google Spread Sheetにデータを吐き出します。
ページのURLに対して Import XML関数を呼び出すことで、タイトルタグやディスクリプションなどを吐き出すことができます。
Import XML関数とは
IMPORTXML関数は、サイトから必要な情報を指定し、その部分の情報をスプレッドシートに出力できるような関数になります。 XML、HTML、CSV、TSV、RSS フィード、Atom XML フィードなど、さまざまな種類の構造化データからデータをインポートすることができます。 裏側の仕組みとしては、サイトをスクレイピング(特定の目的を持ってWebやデータベースを広く探って「データを抽出する手法」)できる技術です。 support.google.com
ImportXMLでタイトルを抽出する
抽出したいURLに対して下記の関数をセットするだけで、データを取得できます。
=IMPORTXML(A1,"//title")
実際に実行した画像がこちらになります。正しくタイトルタグが抽出できていることが分かりますね。
 ウェブサイトやブログに寄っては、SVGを利用していることもあるため titleが複数存在する場合もあります。その場合は、INDEX関数を利用することで一番最初のtitleタグを抽出しましょう。
ウェブサイトやブログに寄っては、SVGを利用していることもあるため titleが複数存在する場合もあります。その場合は、INDEX関数を利用することで一番最初のtitleタグを抽出しましょう。
=INDEX(IMPORTXML(A1,"//title"),1,1)
ImportXMLのデータ抽出に時間がかかる、遅い時はどうする?
先ほど紹介したように、ImportXML関数はサイトへアクセスを行いデータを抽出する処理を行っています。そのためウェブサイトに同時に多数の接続が走ることになるため一度に大量に実行すると時間がかかりすぎてしまいます。解決策としては、同時接続を控えるのが最も効率が良いため、一度に処理するのは10~20までにしておきましょう。